If a verse starts with a number, the alignment and order of elements in the app is incorrect.
The underlying usfm is
Since RTL is confusing, the logical order is \qspace\vspace\4hidden-RTL-markerspace8arabic-full-stopspace/hazrat/
In the app, this is what I see
So, the problem is that the “4” is showing up between the 8 and the full stop, rather than in the correct location to the right.
PT adds in a RTL marker (\u200f) immediately after the 4. However I manually edited the text file to remove that marker and it did not fix the problem, so I don’t think it’s causing this order reversal.
I realized that the bug is being caused by the setting inside SAB saying that the Main Collection, Styles, Text Direction = “Right to Left”. It’s not being caused directly by the Arabic script, and since it’s easier to read Latin script, I created the example in that.
I wonder if, when you tested it, you didn’t set the text direction to RTL.
Inside the Viewer tab, when I click “View in Browser”, then in Firefox I see:
No I did not set the text direction to RTL. Now I do, I see what you see.
As it was happening in Chrome and Firefox I thought it was a bigger problem.
But it can be easily fixed in the HTML.
The HTML looks like this:
<div class="p"><span class="v">‏1</span><span class="vsp"> </span>this is a regular sentence<span id="bookmarks1"></span></div><span id="bookmarks1"></span><a id="v2"></a>
<div class="p"><span class="v">‏2</span><span class="vsp"> </span>1 this one begins with a number<span id="bookmarks2"></span></div><span id="bookmarks2"></span><a id="v3"></a>
<div class="p"><span class="v">‏3</span><span class="vsp"> </span>2. because it is a list<span id="bookmarks3"></span></div><span id="bookmarks3"></span><a id="v4"></a>
<div class="p"><span class="v">‏4</span><span class="vsp"> </span>3: of different things<span id="bookmarks4"></span></div>
The text direction character is before the
If we move the ‏ anywhere after the verse number. All is good.
<div class="p"><span class="v">2‏</span><span class="vsp"> </span>1 this one begins with a number</div><span id="bookmarks2"></span><a id="v3"></a>
<div class="p"><span class="v">3</span>‏<span class="vsp"> </span>2. because it is a list<span id="bookmarks3"></span></div><span id="bookmarks3"></span><a id="v4"></a>
<div class="p"><span class="v">4</span><span class="vsp">‏ </span>3: of different things<span id="bookmarks4"></span></div>
We get this:
Thinking more about the HTML. We can also get the same result by replacing the with a regular space. The NBSP is a joiner So having it there is like having regular numbers. 23 4: comes out as :23 4 the same as if we had 234: showing as :234
I’ll write this up. RTL folk is the second solution better than the first? It may cause orphan verse numbers (the thing NBSP is trying to prevent). Though I am not sure the fist option won’t cause that too.
Thanks for tracking that down. This isn’t the first time I’ve seen programs overzealous in adding RTL markers in places where they aren’t strictly necessary (PT is a big culprit).
Now that I see how you tracked down the problem, I did some experimenting with the html and would like to offer a 3rd option.
<div class="p"><span class="v">2</span><span class="vsp"> </span>‏1 this one begins with a number<span id="bookmarks2"></span>
Specifically, strip the Èf; in most cases, and only add it back in when the text happens to begin with a number (and then directly before than number).
My logic is:
I think you want to avoid removing NBSP for the exact reason you’ve listed–orphaned verse numbers.
I think the Èf; with relation to the verse number is completely extraneous. I think the regular bidi algorithm would always handle putting the verse number in relation to the text, and so over-marking with a RTL marker isn’t neede.
The exception to #2 is when the text begins with a number, as we see here. Since it’s this second number that’s causing the problem, it makes sense to me that it’s the one that should be marked.
I don’t think your third solution would prevent the orphan verse number. You are effectively breaking the join with the ‏ character thus splitting the verse number from the following number.
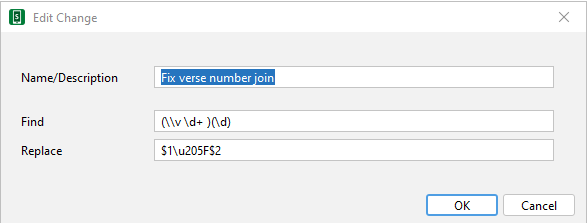
I tried with Changes to effect the outcome but any space inserted before the number following the verse number gets stripped out by SAB processing.
I finally found a non printing character SAB does not account for as a space.
It produces this in the app.
I don’t think there is a way to prevent verse orphans. The sample could also produce a verse number with :3 at the end of a line too. If you use the number better to put a NBSP after the colon.
I am more concerned by the second last line than the third last line.
I’ve done enough research to be convinced that SAB (and Gecko or WebView or whatever it uses) are using the Unicode bidi algorithm correctly. While 1 space 2 is supposed to look like 2 1 in a RTL context, unicode also says that 1 NBSP 2 is supposed to look like 1 2. I’ve written an email to someone I know to find if there is a way in Unicode to handle this in the manner we want.
If there isn’t, then it will probably take some ugly html code to fix the problem, and I’ll leave it to people more knowledgeable than me to say what that should be. Using the css code white-space: nowrap; instead of might be a place to start.