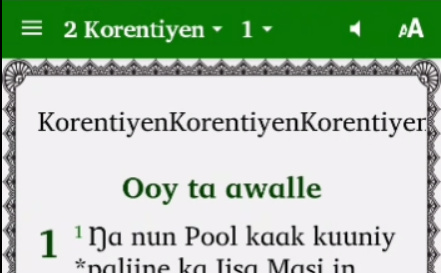
I’m really baffled about this. In both SAB 6.0.2 and 6.1, when I have a book name that begins with a number, the app created drops the main book title and the book introduction (i.e. it’s not selectable from the menu or swipable), and inserts “extra” unformatted book names at the beginning of chapter 1.
So for SFM input like this:
\id 2CO
\h 2 Korentiyen
\toc2 2 Korentiyen
\toc1 2 Korentiyen
\mt1 2 Korentiyen
\mt2 Maktumne ta seeriŋkar taat Pool siirtu ɗo gee ku Korent
\imt1 Pile ka kaawor
\ip Maktumne ta seeriŋkar-an oki, ŋa Pool kat siirta. Ŋa siirit ɗo kretiyenna kuuk goy ɗo geeger ka Korent, asaan ŋu goy di eera
This is what I get in the app:
And the book intro has disappeared.
If I put a non-breaking space before the “2 Korentiyen” in the \h, \toc2, \toc1 and \mt1 lines, then it builds the app properly. (I do this by putting a “~” before the number, then applying a change in SAB under Changes.) I haven’t exhaustively tested to know if some of those non-breaking spaces are not required.
So I have a work-around, but I can’t believe that other people haven’t seen this, unless I’m doing something weird on my end. Can anyone confirm this behavior on their apps? If so, this is a show-stopper!
Jeff, please could you send us the USFM files that are causing this problem. That will help us to reproduce it more quickly. I have not seen this before.
This issue has been resolved! It turns out it wasn’t an SAB bug, but resulted from an over-stretch of a regular expression change in the project. The space is used as a thousands separator for numbers in the text (e.g. 10 000), but we don’t want numbers broken across lines in the app, so we added a Change rule in the SAB project to change those spaces between numbers into narrow non-breaking spaces:
Find: (\d) (\d)
Replace: \1\u202f\2
I thought the change was fine because where else would there be two numbers separated by a space? Well, it turns out that these lines also have two numbers separated by a space!
So the change replaced the space after those markers with \u202f, which no doubt made that space and the following number part of the marker, SAB could no longer parse those markers, and made a mess of the app. That explains nicely why Korentiyen kept appearing in the text. I’m not sure I can explain how the introduction got moved down to replace the last chapter of the book, but fixing this problem seems to take care of that problem as well.
The expression I use instead is:
Find: ([^a-z]\d) (\d)
Replace: \1\u202f\2
The only place a number would appear immediately after a letter a-z is in an SFM, so exclude the possibility of that first number in the search being part of an SFM.
Although this is not actually a bug in SAB, @richard SAB could be made more flexible (robust?) to accept different spaces after an SFM marker. When it is parsing an SFM file, instead of looking for exactly a single space (\u0020) after an SFM marker, maybe you could use the regular expression \s+ instead. That would allow multiple spaces, a tab, or even weird non-breaking spaces like I managed to introduce.