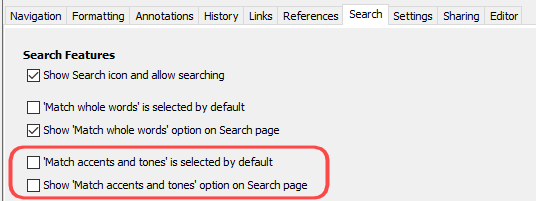
I am wondering whether one of the Search options (under Features) was designed to do something like this (except that it currently only specifies accents and tones). Perhaps it could be extended to other groups of characters that should be ignore when searching.
In my opinion, the tatweel should always be ignored. This character is simply used as a line filler, extending the baseline to make a word longer and better fill the line. Note that this character isn’t even mentioned in the PDF Raja pointed to, as it is a different kind of thing.
I think the characters in Raja’s PDF should not always be ignored, but I think adding the “Match accents and tones” option to the app is a great way to handle this issue. So Raja - you would need to add this option to your app configuration, as shown in mjpenny’s screen shot above. I would recommend checking both of the boxes that he circled in red. It won’t work yet for you, but once this change is made in SAB, the user can check this box on the search page in the app to ignore the harkat/tashkeel when he is doing a search.
And to the developers: I assume the tatweel (always) and the other characters (only if the option is checked) would be removed from the search text in addition to the text being searched? I could imagine a case where someone copies a word with tatweels and pastes it into the search box, but if you are removing tatweels from the text being searched, it wouldn’t be found unless you also removed the tatweels from the search text. Just a little sanity check… ![]()
All of the harakat characters in that document have an Mn category (Nonspacing_Mark) and that is the same category for other combining marks like acute and grave. So, I’d hope that turning off “Match accents and tones” might be the solution to the problem.
Also, I do know that in some cases tatweel/kashida is used as a mark holder (for example: tatweel plus combining hamza). In any case, the combining mark you would like to be ignored so maybe it’s okay to ignore tatweel as well.
Agreed!
It will better to add an option in search option menu either to ignore harkat/tashkeel or to search with harkat/tashkeel.
Raja,
I have reread your posts in TeamHelp and here.
You were asked the question “What are your settings for Features / Search?” That is the settings found that are like the picture below from SAB?
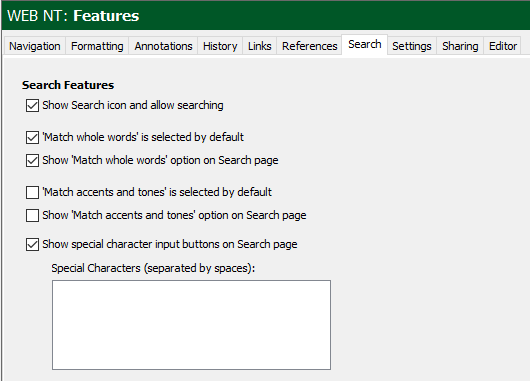
We need to know an answer to that question.
Have you tried different settings?
What differences do you see?
I have tried all these setting one by one, but all in vain.
After trying all possible options, I put my question in front of you.
Thanks for that clarification.
Although we have not yet got to that, an APP is planned for an Arabic script language including vowels. This is in the future, but it is good I see this communication. I can not yet say anything about the FEATURES/SEARCH OPTIONS but I can say something about the vowels & signs ( tashkeel) that should be ignored for this upcoming APP. First I give you a link to a very nice and detailed overview of all Arabic Unicode characters (vowels, letters, digits, signs):
https://www.key-shortcut.com/en/writing-systems/ﺕﺏآ-arabic-alphabet/
On the right side of the page you can choose COMPACT or COMPLETE … bot are very helpful.
When you choose COMPACT you will see the Unicodes.
In my case U+063B up to U+0657 should be ignored.
in the SEARCH section of SAB
Everything that is named LETTER does not belong to TASHKEEL, same for DIGITS and LIGATURES. This for your information.
Nice to hear from you.
U+063B to U+064A are the main letters, these must be included in search option.
But the range, to be ignored, is from
U+618, U+64B to U+658, U+670
Hi Dear
@mcquayi @jeff_heath @mjpenny @Lorna @joop
Please any progress regarding the issue…
waiting for help…
Sorry, I agree with Raja about the range to be ignored:
U+0618, U+064B to U+0658, U+0670
I made a mistake in my message. Sorry!
1 Like
I propose the following new feature in SAB. Under Features > Search, we add 3 more options:
[ ] 'Match vowel markings' is selected by default
[ ] Show 'Match vowel markings' option on Search page
Vowel markings to ignore:
[empty text box]
Notes:
- This could be useful for more than just Arabic, especially if the phrase ‘vowel markings’ as seen by the end user is configurable.
- Alternative A: fill the ‘to ignore’ text box with this list by default:
U+0618,U+064B,U+064C,U+064D,U+064E,U+064F,U+0650,U+0651,U+0652,U+0653,U+0654,U+0655,U+0656,U+0657,U+0658,U+0670 - Alternative B: allow ranges, so the above list would be:
U+0618, U+064B - U-0658, U+0670 - Alternative C: use a regular expression rather than list of characters (difficult to type and visualize), e.g.
s/[ًؘ-ٰ٘]// - All of the text should be converted to be Unicode decomposed form before stripping.
- Both the text being searched and the search field should be stripped of the ‘to ignore’ characters before comparison.
- For more information on Arabic diacritics, see the Wikipedia page: Arabic_diacritics (I’m not allowed to post links).
- In a different Arabic dialect, this is the proposed list of characters to strip:
U+0618 - U+061A, U+064B - U+0652
Would this satisfy everyone? Are there better ways of doing this?
1 Like
Good Idea!!!
It will be a great feature and I think it is the resolution of the said issue…
Furthre, our developers know more and very well.
I disagree. For one thing, I think you are just picking the characters that are important to you. For example, you say to exclude U+0618 ARABIC SMALL FATHA, but what about U+0619 ARABIC SMALL DAMMA? It is an almost identical character, and it may not be important for you to ignore, but it could be important for the next guy. And I also disagree with adding more check boxes in the app. Your ‘Match vowel markings’ is really the same thing as the ‘Match accents and tones’ option that exists already. You just want to change it to fit your specific need.
So I propose something much simpler. I propose that when ’Match accents and tones’ is not checked (i.e. you want to ignore accents and tones), it automatically ignores everything that is added to a base character (which includes Arabic vowels and combining diacritics in the U+0300 block), as defined in the Unicode standard. These characters all have a General_Category in the Unicode Character Database of:
Mn Nonspacing_Mark a nonspacing combining mark (zero advance width)
FYI - the Unicode Character Database is found here:
https://www.unicode.org/Public/UCD/latest/ucd/UnicodeData.txt
And this is a description of how to read it:
https://www.unicode.org/reports/tr44/
What is currently ignored by the code if ‘Match accents and tones’ is not checked? Obviously apps currently created with the App Builders don’t ignore all of these characters marked Mn. If they did, then we wouldn’t be having this discussion, because all of the Arabic vowels are marked Mn, and could be easily ignored with the options currently available.
So I would propose that if the ‘Match accents and tones’ box is not selected, then app searches should ignore anything marked Mn in the database. This should be easy to do programmatically. (Programmer notes: In Python, I use if unicodedata.category(letter) == 'Mn'. And you would need to remove Mn characters from both the search word and text searched, before you do the comparison. I imagine ignoring all Mn characters would actually make the code simpler than it currently is, since currently it ignores just some select subset.)
I don’t think it’s a problem for Arabic users to have to figure out that ignoring accents and tones includes vowels. But if you are insistent that the checkbox should say something about vowels, then we could add a field "Custom text for ‘Match accents and tones’ " - and you could put your vowel text there. But its function really is replacing accents and tones, and I think Arabic users should be able to figure that out.
If we follow this proposal to ignore all the Mn characters, I think the field at the bottom needs to change. Right now it says, “Specify the replacements and diacritics to remove if not matching accents and tones.” For one thing, I think it should appear above the input buttons fields, right under the ‘Match accents and tones’ checkboxes. And I have trouble understanding the double negative. I think it should try to explain the combining marks first, then invite additional removals or replacements, something like this:
Ignoring accents and tones will automatically ignore nonspacing combining marks (as defined in the Unicode standard), things like combining diacritics and Arabic script combining vowels. Specify here (separated by spaces) any additional characters to ignore, or replacements to make in the search text. E.g. ‘é>e è>e’ would allow those two composed characters to be found with a simple ‘e’ in the search string. The string ‘_ -’ or ‘\u005F \u002D’ would ignore underscores and hyphens in the search. (Note that you can use \uXXXX to define a character by its Unicode hex code.)
I think making these changes will probably serve the needs of 99% of users. The cases that aren’t served are when a user doesn’t want to ignore certain characters marked Mn, but does want to ignore others. Because with the above, if you choose to ignore, all of the Mn characters will be ignored. I personally can’t think of a case when this would be needed. But I think 99% of those 1% of cases could be served by adding another simple field (below the field with the long explanation) that has this label:
Enter here characters to ignore or replacements to always use in the search, even when ‘Match accents and tones’ is selected.
I would think in this case you wouldn’t even want to show the ’Match accents and tones’ option on the Search page.
So that’s my proposal. I don’t think it would be very much work for the developers to implement (especially if we didn’t add the second field, but just kept the original field, changed its label and moved it up on the configuration page). And I think it makes more sense than making even more specific search criteria basically just for Arabic.
Previously we talked about always ignoring U+0640 ARABIC TATWEEL. I think that should still be done. But other characters would be ignored based on their character type, and whether the box is checked or not.
1 Like
Just FYI - there are 96 Arabic characters that are marked Mn in the Unicode standard. The best way to find them is to look for the dotted circle “base” under combining characters on the 3 Arabic Unicode code pages (links below). But you can also search for “;Mn;” in the Unicode Character Database.
Can we get an indication from the developers about implementing this proposal? As I mentioned, if you use the Unicode character category, it shouldn’t be that difficult to implement. And given that there are no further comments after my proposal, does that mean everyone agrees that it is the best way to go?
Jeff, thank you for the good description and discussion. You have helped me understand this much better.
I have been testing the results of putting 11 Unicode characters (all Mn characters) in the “Specify the replacements and diacritics to remove” box in SAB. I’m not sure why I didn’t try this before. This is what I entered:
\u0618 \u0619 \u061A \u064B \u064C \u064D \u064E \u064F \u0650 \u0651 \u0652
When “Match accents” is unchecked, it appears to actually allow the user to search without the need to type the vowel markings. 
However, when the user types the vowel markings, I would expect it to find matches regardless of “Match accents”, but it finds nothing unless “Match accents” is checked.
Tomorrow I hope to study my test results further and better understand what is going on. I’d love to hear other’s thoughts.
Here are some of my test results:
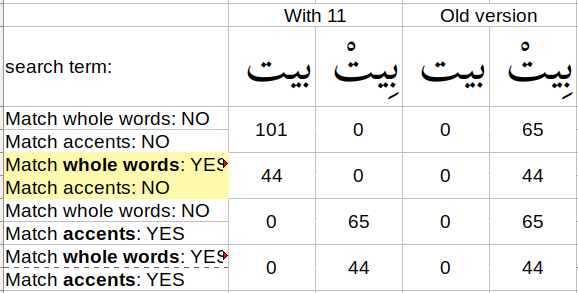
P.S. I didn’t realize that there was further discussion on this until yesterday. I thought it would notify me by email, but apparently I needed to select “Watching”.
@jeff_heath - How do you feel search should work if the user types the vowel markings?
@Raja_Sand - Can you test this approach with you app? For the first test, I would suggest you put your list from above in the “Specify the replacements and diacritics to remove” box in SAB:
\u0618 \u064B \u064C \u064D \u064E \u064F \u0650 \u0651 \u0652 \u0653 \u0654 \u0655 \u0656 \u0657 \u0658 \u0670
Based on what Jeff said, I’m working on a theory that the optimal list of characters to put in this box is the subset of the 1826 Mn code points that actually exist in your text. You can find this on Linux (or WSL on Windows 10) via:
sudo apt install -y icu-devtools
wget -O /tmp/UnicodeData.txt https://www.unicode.org/Public/UCD/latest/ucd/UnicodeData.txt
grep '\bMn\b' /tmp/UnicodeData.txt |grep -o '^[0-9A-F]*\b' >/tmp/CPs_with_Mn
cd <directory with your Paratext SFM files>
cat * |uconv -x any-nfd |perl -C7 -ne 'for(split(//)){print sprintf("%04X\n", ord)}' |sort |uniq >/tmp/CPs_used_in_text
cat /tmp/CPs_used_in_text /tmp/CPs_with_Mn |sort |uniq --repeated |perl -pe 's/^/\\u/; s/\n/ /'; echo
1 Like
@jeff_heath
@expebition
A millions of thanks.
That worked perfectly.
Really I don’t have words to express my feelings.
It worked like a charm.
Humble regards.
1 Like