Can we get an indication from the developers about implementing this proposal? As I mentioned, if you use the Unicode character category, it shouldn’t be that difficult to implement. And given that there are no further comments after my proposal, does that mean everyone agrees that it is the best way to go?
Jeff, thank you for the good description and discussion. You have helped me understand this much better.
I have been testing the results of putting 11 Unicode characters (all Mn characters) in the “Specify the replacements and diacritics to remove” box in SAB. I’m not sure why I didn’t try this before. This is what I entered:
\u0618 \u0619 \u061A \u064B \u064C \u064D \u064E \u064F \u0650 \u0651 \u0652
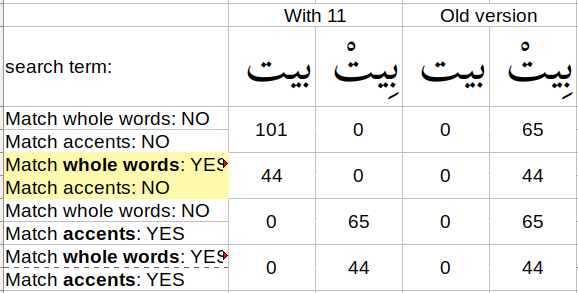
When “Match accents” is unchecked, it appears to actually allow the user to search without the need to type the vowel markings. 
However, when the user types the vowel markings, I would expect it to find matches regardless of “Match accents”, but it finds nothing unless “Match accents” is checked.
Tomorrow I hope to study my test results further and better understand what is going on. I’d love to hear other’s thoughts.
Here are some of my test results:
P.S. I didn’t realize that there was further discussion on this until yesterday. I thought it would notify me by email, but apparently I needed to select “Watching”.
@jeff_heath - How do you feel search should work if the user types the vowel markings?
@Raja_Sand - Can you test this approach with you app? For the first test, I would suggest you put your list from above in the “Specify the replacements and diacritics to remove” box in SAB:
\u0618 \u064B \u064C \u064D \u064E \u064F \u0650 \u0651 \u0652 \u0653 \u0654 \u0655 \u0656 \u0657 \u0658 \u0670
Based on what Jeff said, I’m working on a theory that the optimal list of characters to put in this box is the subset of the 1826 Mn code points that actually exist in your text. You can find this on Linux (or WSL on Windows 10) via:
sudo apt install -y icu-devtools
wget -O /tmp/UnicodeData.txt https://www.unicode.org/Public/UCD/latest/ucd/UnicodeData.txt
grep '\bMn\b' /tmp/UnicodeData.txt |grep -o '^[0-9A-F]*\b' >/tmp/CPs_with_Mn
cd <directory with your Paratext SFM files>
cat * |uconv -x any-nfd |perl -C7 -ne 'for(split(//)){print sprintf("%04X\n", ord)}' |sort |uniq >/tmp/CPs_used_in_text
cat /tmp/CPs_used_in_text /tmp/CPs_with_Mn |sort |uniq --repeated |perl -pe 's/^/\\u/; s/\n/ /'; echo
1 Like
@jeff_heath
@expebition
A millions of thanks.
That worked perfectly.
Really I don’t have words to express my feelings.
It worked like a charm.
Humble regards.
1 Like