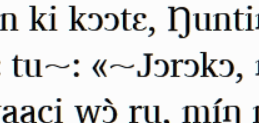How helpful that there’s a gallery from which to select pre-made regex patterns!
It was suggested in the Asia LT meeting with Ian McQuay just now that users should suggest useful Change regex rules for inclusion in the gallery.
For those who have adopted the convention of repurposing the \fig marker’s obsolete loc field to tag the output locations (print/app/web) for the figure, the following change rule will filter out figures that are tagged for only print (‘p’) or web (‘w’) and not app (‘a’):
Name: Filter out figures tagged only for print (p) or web (w) locations, not app (a). [USFM 2 version]
Find: (?i)\\fig ([^|]*\|){3}([pw]+)\|[^\\]*\\fig\*
Replace: {leave empty}
To be ready for Paratext 8.1’s figure syntax, a second rule is also needed:
Name: Filter out figures tagged only for print (p) or web (w) locations, not app (a). [USFM 3 version]
Find: (?i)\\fig [^\\]*\bloc="[pw]+"[^\\]*\\fig\*
Replace: {leave empty}
(Technically, these could be combined into one rule, but if the user ever needed to adjust the output location codes for anything other than a/p/w, a combined regex would be harder for them to recognize where the adjustment would be needed.)
For more details on this convention, see tiny.cc/tagoutput (Sorry it’s not clickable. It says “new users” can’t post links.)
What other suggestions do people have for the changes gallery?
Dan, I am wondering if there should be a User defined changes list that can be imported and exported. And those could be shared on a website where more fuller documentation could be seen to see what it does.
If we load up the presets with many complex options it becomes harder and harder to find the commonly used ones the majority want to use.
One thing was clear from the Asia discussion is that some Non-Roman scripts have to do a lot more work on the texts to get good results in the app. Mark had about 20 changes in his example. Nic was doing some complex changes to make audio sync work better.
Here’s a simple change rule I created just yesterday to make sure that spaces before certain punctuation are turned into narrow non-breaking spaces:
<change name="Make space before punctuation narrow non-breaking space">
<find> ([:;?!])</find>
<replace>\u202f\1</replace>
</change>
This is a critical rule in French-speaking contexts, because the French standard is a (non-breaking) space before these punctuation marks, but many French-speaking teams just type a normal space, e.g. here’s a sample from my text:
\c 7
\p \v 1 Wa Aliyaasaʼ radda leyah wa gaal : «Asmaʼo kalaam Allah !
Daahu Allah gaal : ‹Ambaakir fi nafs al-saaʼa...
If I pull that text as-is into a Scripture app, there are a number of places where punctuation could end up at the beginning of a line, depending on text zoom, e.g.:
Wa Aliyaasaʼ radda leyah wa gaal
: «Asmaʼo kalaam Allah ! Daahu...
Ugly! So this rule changes the plain space before the punctuation into a narrow non-breaking space to force it to be with the preceding word:
Wa Aliyaasaʼ radda leyah wa
gaal : «Asmaʼo kalaam Allah !
Daahu...
In a specific project there might be rules needed for spacing around quotation marks as well. For this project I added two rules for adding narrow non-breaking spaces after opening quotes and before closing quotes:
<change name="Add narrow no-break space after open quotes">
<find>([«‹])</find>
<replace>\1\u202f</replace>
</change>
<change name="Add narrow no-break space before close quotes">
<find>([»›])</find>
<replace>\u202f\1</replace>
</change>
This sets them off nicely in the app. These rules might be too specific to put in a general gallery (there are a number of ways to deal with quotes, both in the source text and in the output), but a number of teams might still find them useful.
Yes, an import/export mechanism would be helpful. My experience with copy-paste from a web page is that users inevitably copy and paste regexes wrong. (extra spaces, etc.) Yet this is what we are currently relying on in tiny.cc/indictypesetting where we provide these regexes for app builders.
It might also help to organize the gallery if gallery items could be organized into groups. e.g. Punctuation, Images, etc, and if each item could provide descriptive HTML to explain why you might need it, and how to use it (if user-customization is necessary).
In many cases there are illustrations in a print version of the Bible which the illustrator does not currently permit to be present in apps. The following regex line will remove those particular illustrations, and make it easy to put them back in later if the illustrator allows.
\.(?i)(jpg|png|tif)(.*?)Horace Knowles
\fig Grapes on a grapevine|hk00111c.tif|col|Mak 12:1|Horace Knowles|(Mak 12:1)| \fig*
Some of the Regex elements:
(?i) - makes the search case insensitive
(.*?) - the question mark makes this non-greedy
This regex line works very well in all cases except where there are two illustrations within a single line. For instance, in the line below, there are two .tif file names in one line. I couldn’t figure out how to only capture the later in any clean fashion. I tried negations and negative look aheads, but didn’t manage to succeed. If someone has a good idea, I’m all ears.
…mum nɛ gɛn ketum kemew e.\fig Vineyard with watchtower and wine press|LB00103C.TIF|span|Mak 12:1|Louise Bass|(Mak 12:1; Mat 21:33-46; Luk 20:9-19)| \fig \fig Grapes on a grapevine|hk00111c.tif|col|Mak 12:1|Horace Knowles|(Mak 12:1)| \fig*
I believe a broader solution than this is necessary, as the converse is often required: Certain images (especially color images) are to be used only for electronic publications, and not for print. The solution we use in South Asia is to make use of the obsolete “Location” field, as documented for users here. The regexes you’ll need for that, both for the current USFM2 and the upcoming USFM3, can be found here (in the Illustrations section). This should also handle the problem of two illustrations in the same line of text.
I know this thread is very old, but I’m trying to use the “Changes” feature to change a breaking space before a semi-colon to a non-breaking one. I put \s\u003B in the “find” field and \u202f\u003B in the “replace” field. This doesn’t work. I tried \0020 instead of \s and still no success. In reading through the above suggestions, how do I put in a regular expression? In Jeff’s example change rule, how do I put that in SAB using the “find” and “replace” fields. What exactly would I type in each field?
Thanks!
Andrew
I am going back a bit far in the cobwebs here but I seem to remember something about the Changes not finding unicode characters, only replacing them…I may be totally misremembering this, but just try this to see if it works:
Did you get this figured out? You should be able to use Unicode codes in the find, but I would probably suggest:
Find: “\s*;”
Replace with: “\u202f;”
This finds zero or more spaces before a semicolon, and changes them to the narrow non-breaking space.
If you can’t get it to work, show us a bit of your source file, both with and without the “Show After Changes” box checked at the top.
Note that this will put a \202f character before all semicolons, even ones in references, like this: \r (Matiye 3.1-6,11-12 ; Lik 3.1-6,15-18)
That may be fine, but you just need to make sure that’s what you want.
The find finds one or more spaces before a semicolon.
There is some inconsistency in the markup:
There is a space after the 17 then another space after the \xt* There should be no spaces before the \xt* That will cause unexpected wrapping and ; to occur at the beginning of lines…
Description: Remove space inside \xt at the end
find= \\xt\*
replace=\\xt*
That seems to work fine. I have ; ending lines but none starting lines.
I do see that maybe a change to put a non breaking space after any * would stop those appearing at the end of lines. Then do you add a non breaking space between 1 and Piyer, and the other books that have number in front?
Numbered books: find=(\d) ([PTVS]) rep=$1\u202F$2
Asterisk before space: find=\* rep=*\u202F
It is also possible to make a change for the hyphenated verse numbers in the \xt they could be changed to non breaking hyphens.
I don’t understand why the ; needs to have a space before it. It looks odd to have floating at the end of many lines.
Another project, but same issues. An African language using French punctuation rules and I’m seeing inconsistency in the highlighting (note there are spaces before and after exclamation points in French, but not before full-stops (periods)). Quotes in French are like this << and >>. I use the “Changes” feature to turn them into true French guillemets.
I have SAB set to change spaces before colons, exclamation marks and end quotes to be non-breaking.
bonjour ! >> he said ------------> this highlights bonjour and the ! but not the closing quote. The closing quote get highlighted with “he said” (not correct)
bonjour >> ; he said ------------> this highlights bonjour, the closing quote, the space and the “;” (which is correct)
bonjour >>, he said --------------> this highlights bonjour, the closing quote and the comma (which is correct – note no space between >> and ,)
bonjour. >>
He said --------------> this highlights bonjour, the full-stop and the closing quote (which is correct) “He said” is a new line.
bonjour. >> He said --------------> this highlights bonjour and the full-stop, but not the closing quote, which gets grouped with “He said” (Not correct! The "He said is on the same line, and apparently that throws aeneas off)
A trick I learned last week is to insert a Zero width space in the place you want phrases to break with changes. It won’t be visible. Then change your phrase breaking characters to the zero width space.
But you will need to be carful that you don’t insert some in the wrong place thus creating two breaks where there should be one. I have not tried this.
Hello Jeff,
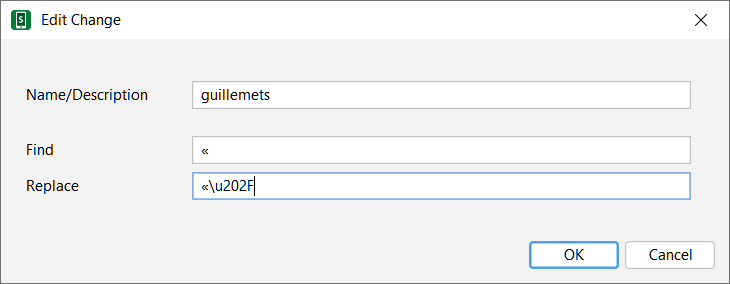
This was a while back and I am wondering if there was a decision about adding : the addition of a narrow non breaking space with guillemets in french spelling to the Changes Gallery ?
Let me show you a printscreen:
Looks like in your output you have a \u202f AND ALSO a non-breaking space, that got in there from the ~ in your text.
If you consistently have «~ then you can search for «~ and replace it with «\u202f.
Another possibility is to search for «\s*. This should find all open guillemets followed by zero or more space characters. That would be my preferred solution.
You were right, it was indeed the double effect. I corrected that and here is the result:
… tu\u202f:\u0020<<\u202fÁ (see screenshot below)
Now, according to the normal implementation of \u202f in fonts, it should be narrower, 70% of a normal space. (Maybe that was not respected in Charis, so in that case it could be a design-flaw). To my eyes at least, the difference is barely visible and slightly disappointing. Do you know of a way to make the narrow_space between tu and : and between << and Á clearly more narrower, whilst maintaining the unbreakableness? (Some CSS character style magic ?)
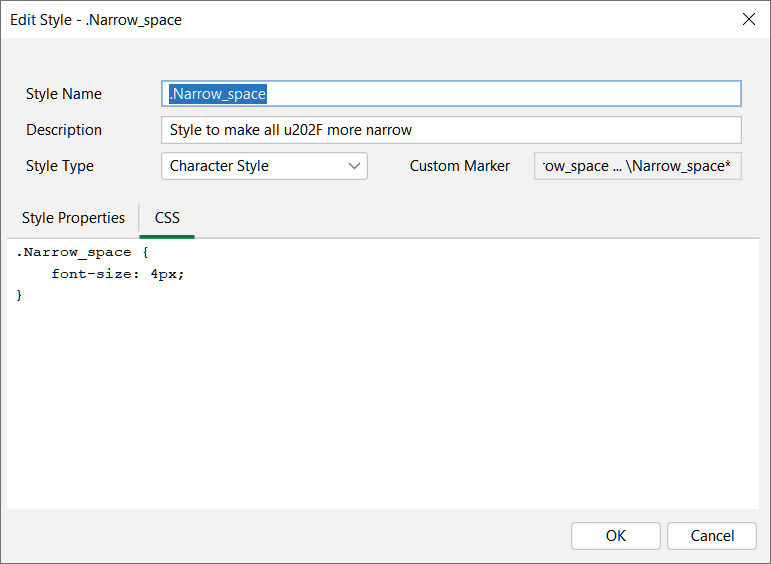
I don’t know if that would work or not, but you can give it a try. The way to apply that style in HTML would be something like this:
<span class="Narrow_space">\u202f</span>
You could try putting that whole string in your replacement string, but no guarantees whether that will work or not.
Also, I would name your style based on what the style gives, not by how you are going to use it. Yes, you want to use it to make a narrow space, but it is just a tiny font, so I would name it “.tinyfont”, and then use it like this class="tinyfont". Then if you need a tiny font elsewhere for some other purpose, you don’t have to create a new style.