Hi, I’m working on a miracles app i.e. with story pages. Each page has a separate audio clip. On some pages there is a very short phrase without any punctuation except the final period. When I run the automatic synchronisation, it skips those pages and says ‘error no text’. The only way around it is to add a comma, but sometimes that doesn’t make sense to the phrase. The other way I’ve worked around this is by manually creating a timing file for that particular page. Any suggestions of how to fix this? Thanks! Janet
Can you replace a space with a no-break space and add that character as punctuation?
Hi, thanks for the idea. How do I make a no-break space?
In Word it is usually Ctrl+Shift+Space. You will know it worked if it keeps two words together.
I’ve tried doing this, but it doesn’t seem to work. I edited my text sfm file (not in Word),adding a no-break space in the phrase. When I did ctrl+shift+space it seemed to work as it didn’t visibly add anything. When I ran the audio synchronization, I added the no-break space to the list of punctuation too as you suggested. However, it still gave me the same error and didn’t create a timing file for that page.
USFM uses ~ for a non-breaking space. You will have to test this to see if it converts correctly and if Aeneas works with it.
Could also try copying this space (hopefully it doesn’t copy as a normal space):
and put \u00A0 in the Phrase-ending characters.
The other option might be to add a zero-width space which does not join the words together (leave the normal spaces in and add at the end of the word). These are difficult to copy/paste as they are not visible, but here goes:
Put \u200B in Phrase-ending characters.
The ~ doesn’t seem to be recognised by Aeneas. I tried various ways to do this to no effect.
For your second idea, I copied and pasted what you had put, but added a return to my text.
I’ve found another temporary solution for the pages where this is an issue. I have added \s to indicate that a space is a phrase break just for that page, now the audio synchronisation is syncing with each word, but as there are only 3 words on the page, that’s fine.
But if you come up with a better idea, please don’t hesitate to send it! Thanks!
Try opening a new word document and type Ctrl+Shift+Space and copy the resulting space.
That hasn’t helped unfortunately…
Hi Janet,
After a workshop about a year ago I wrote up a process for syncing without punctuation on the Spanish RAB forum (here) that might help you. I’m busy with meetings this morning, so unfortunately I can’t give you a translation right now, but maybe with Google translate you can at least see the general idea of the steps we took. I’ll work on translation of that writeup into English.
Sorry if I confused things with the link I shared to our write‑up in Spanish. I’ve read this whole thread now and realize that your question isn’t about synchronizing without punctuation in a large portion of text like we were doing. In that write‑up, though, we found that using no‑width spaces worked in Aeneas, when we added \u200b to the list of phrase‑ending characters, as in one of the optiones that Greg mentioned.
It sounds like the problem you’re having, though, is how to paste the no‑width space into your text. In our case, we used SAB’s “changes” feature to define a change that would add the no‑width space (\u200b) to the beginning of conjunctions in the language. In your case, maybe you could add a character that doesn’t occur elsewhere in the text (maybe the pipe: |, or the tilde you tried earlier, etc) to your text where you need a sync break, and then make a change rule to convert that character to the no‑width space. Then with the no‑width space in the list of phrase‑ending characters, maybe Aeneas will work.
The question is … Does Aeneas use the source text or the regex’d text?
I don’t have any audio Bibles setup to test this.
It appears that Aeneas does use the regex’d text. At least based on our results after using the basic process that I descibed above (inserting the no-width space through the “changes” function and then adding it as a phrase-ending character for Aeneas). I did finally translate my write-up from the Spanish forum; I’ll post the English version here in a bit so you can see the details of our process.
Synchronization of audio with text that doesn’t use punctuation between phrases
(This post is a translation of a note on the Spanish RAB forum that documents a process that we came up with during a recent workshop)
SAB and RAB can be configured to synchronize text with divisions defined by conjunctions that introduce new phrases instead of traditional punctuation marks (eg.?!:;,). To configure SAB or RAB for this type of synchronization, the developer needs to
- Identify the appropriate conjunctions,
- Define consistent changes to insert “zero-width spaces” (\u200b) before each occurrence of those conjunctions, and
- Define the zero-width space character as a “phrase‑ending character” in the Aeneas settings.
1. Identify conjunctions
The first step is to make a list of the conjunctions whose occurrence always indicates a clause or phrase change for audio synchronization. This step must be done by someone with knowledge of the grammar of the language at the discourse level to decide which conjunctions will indicate divisions of phrases that must be indicated in the app. Examples of conjunctions in Spanish that could be included in the list according to the level of division of phrases desired would be: y (e), o (u), pero, porque, entonces, aunque, sino, por eso, etc.
2. Consistent changes to insert “zero-width spaces”
Aeneas relies on a list of characters that indicate the end of a phrase to recognize how the text should be split‑up for synchronization. So the second step is to configure RAB or SAB to insert a unique character in the text before each occurrence of the conjunctions identified in the first step.
It is recommended to use the unicode code character \u200b (“zero‑width space”). We use this character because it is a character that is not displayed visually in the app and normally has no other function in the popular orthography.
The place where we define these changes in RAB or SAB is in the area called “Changes” in the app’s feature tree. Clicking on that feature for the first time will present a blank area in the right hand window. Click the “Add Change …” button at the top of the window.
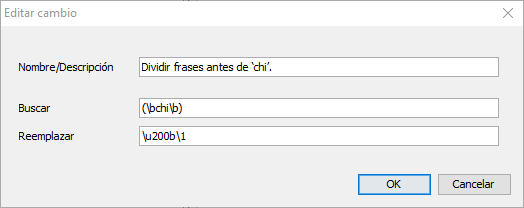
- In the dialogue box that appears, type the description of the change to the first conjunction in the first line (Name/Description).
For example, if one of the conjunctions that indicate a phrase change is the word “chi”, enter a name such as “Divide phrases before ‘chi’.”
- The second line (titled Search) is where we indicate the text we want to change using a type of search known as “regular expressions”. It is not necessary to know much about the syntax of this search convention to make the changes that we are going to make. The two details that are important in our searches are to:
- indicate that we only want to find complete words and not occurrences of those letter sequences within other words, and
- instruct the program to remember each occurrence of the text we’re searching for, so that it can replace each of those occurrences with the same text preceded by the zero-width space.
To meet the first requirement (that the text only finds complete words) we are going to include the code \b before and after the text we are looking for, to indicate that what we are searching for is the occurrence of the letters indicated between 'word boundaries’.
To instruct the program to remember each occurrence, we write all the letters and codes of our text search between parentheses.
So, to indicate, for example, that we want to find every occurrence of the word “chi”, we will write the sequence of characters
(\bchi\b)on the second line of the dialogue box.
- The third line (labeled Replace) is where we can define the text that we want to appear in place of the found text. Here we can indicate characters with their unicode code if we use the
\umarker before their code number. So, to insert the zero‑width space, we can enter\u200bon this line. Then, since we instructed the program to remember the text found above, we can write the code\1after the zero-width space code so that the program inserts the saved text immediately after the zero-width space.
In our example of the word “chi”, the third line will have the text
\u200b\1to insert the zero‑width space before the found word (chi).
The three lines in our example will look like the lines below:
After filling in these three lines, click the “OK” button to accept this change definition. Click the “Add Change …” button again at the top of the window and repeat these steps as many times as necessary to define a change rule for each conjunction.
3. Define the zero‑width space as “phrase‑ending character”
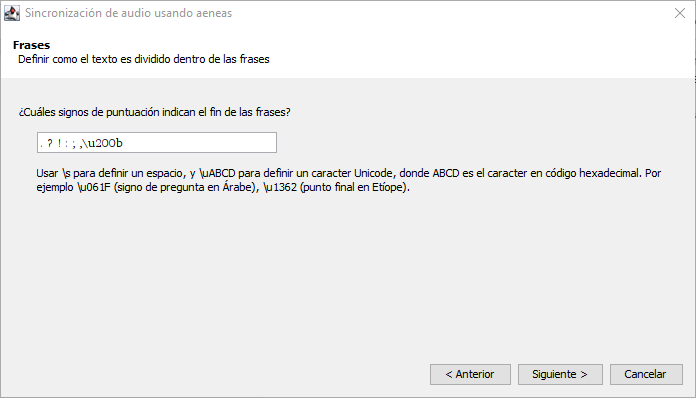
Now that the program is set up to insert the zero-width space before each conjunction in the list, we can run Aeneas as normal, including the zero-width space in the list of “phrase‑ending characters” used to divide text into phrases for audio synchronization.
Clicking on the option “Synchronize using Aeneas…”, we can follow the wizard as normal until we reach the page titled “Phrases” (almost the last page). In this space, where the assistant asks us “Which punctuation characters mark the end of the phrases?”, we need to include the zero‑width space. We include it in this list of punctuation marks using the same code that we used in the second step: \u200b. With the code for this character added to the list, this page of the wizard will look like the image below:
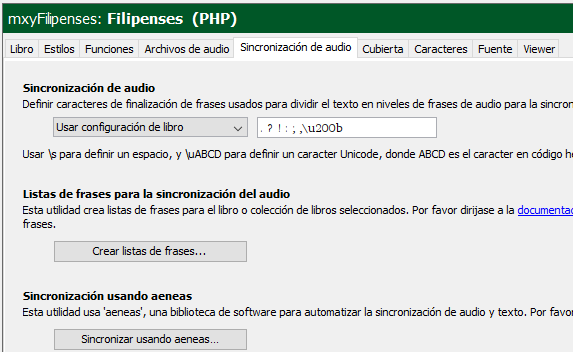
After this setting is applied and the sync complete, the definition of “phrase‑ending characters” displayed in the “Audio synchronization” tab of the book will show that the zero-width space (\u200b) is included:
Use the “Export to HTML” function to confirm the synchronization, or use the “Fine-tune synchronization” function to make adjustments if necessary.
Thanks for your help with this. I’ve tried what you’ve suggested, but have a new problem now! When I try to sychronise, I’m getting a new error : no tasks were created, this might be because you have not specified any audio files.
This doesn’t make sense to me since I first highlight the audio file that I want to synchronise! As I can’t get it to work at all, I can’t see whether the change I’ve put in has solved the previous problem. Any ideas what’s happening now?
Sorry this caused another problem! It looks like some others on this forum have run across that error message from Aeneas:
This post seems to indicate that their problem was caused by moving the project from one computer to another, and not transferring all the necessary files.
Another thread ends with suggestions to
- save your app project in SAB, build the app, close & re‑open SAB and then try to run Aeneas
- make sure audio filenames don’t use non‑standard characters (accents, etc)
- make sure the text you’re synchronizing uses valid punctuation
I hope one of the suggestions in those threads helps you out.
Thanks for passing those solutions on. I’ve just uninstalled SAB and reinstalled the latest version (I was still on 9.0.1). I’ve checked Aeneas is installed and running correctly. It’s strange because yesterday I was able to synchronise without problem and today I can’t. I haven’t changed anything on my computer and the format of the file names is identical to yesterday.
I’ve tried the idea of building the app, closing and re-opening SAB, but nothing has changed
I’ve found the solution!! When I added the vertical bar to the text and made a change to add the no-width space each time the bar was there, this in effect prevented aeneas from synchronizing. After puzzling this over for several hours, I realised that the vertical bar is actually automatically added before each phrase that’s created when running the synchronisation. So it was NOT a good character to add to my text! I tried instead using the % character and to my great relief, the synchronization worked again, AND I got the short sentences without punctuation to synchronize too by adding the %.
So thanks for helping me find my way to the solution and hopefully this might help somebody else too in the future.