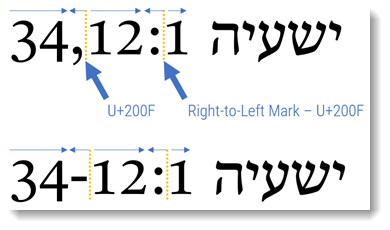
RTL text is weird. Numbers are actually displayed in LTR format. So if you got rid of the colon and the hyphen, the correct display of that string of numbers would be:
 i.e. “1127”, reading left-to-right
i.e. “1127”, reading left-to-right
If I paste the text from your \s above into Word, I get the following (exactly what you are seeing in PTXprint):
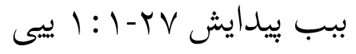
However, if I paste it into LibreOffice Writer, I get the following:
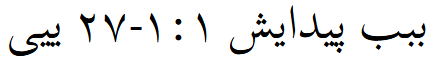
(what you were hoping to get)
In this case, I think Word is actually more correct. The numbers are LTR, and the colon and the hyphen are “Neutral” in their bidirectionality (see Bidirectional text - Wikipedia). That means that they don’t force a direction on the text, but take it from the surrounding context. And since they are in the context of LTR characters (the numbers), they should keep the LTR direction, and that whole string of numbers and punctuation should be presented on the line in an LTR direction, as PTXprint is doing.
So from that perspective what PTXprint is producing is theoretically correct (from the bidirectional text algorithm). But that’s actually not what you want. We are reading our text RTL, and we want the different chunks (separated by punctuation) to appear one after the other from RTL, like shown in the LO Writer output above. (I don’t actually know why the LO Writer output is like that. It doesn’t seem like it is following the Unicode bidi algorithm…)
But I can get that behavior in Word by adding special marks called Right-to-left marks. They are Unicode codepoint U+200F (see Right-to-left mark - Wikipedia). You can insert these marks after a punctuation to force an RTL text direction for that punctuation. To do that in Word, put the insertion put after the colon (I would recommend using the arrow keys to find that spot), type “200F” and type Alt+X (hold down the Alt key and tap the X key). Your chapter one should now jump to the right of your string of numbers and punctuation. Do the same after the hyphen, and your string will look the same as the LO Writer output above.
But now the tricky part is getting those RTL marks inserted in the text for PTXprint. I haven’t tested this, but I think you might be able to use Changes.txt (on the Advanced tab) to create rules that will insert the RTL marks in the proper places. Try these rules (untested):
'(\d):(\d)' > '\1:\u200f\2'
'(\d)-(\d)' > '\1-\u200f\2'
But there is one more interesting issue. I notice that you are using the Eastern Arabic-Indic digits, which start at U+06F0. (See https://www.unicode.org/charts/PDF/U0600.pdf.) I’ve mostly used the plain Arabic-Indic digits, which start at U+0660. I think the \d digit designation should work for those digits as well, but if it doesn’t, you might need to use something like this: [\u06F1-\u06F9] in place of \d.
Anyway, that gives you something to try. And we’ll all be interested to know if you make progress!
Jeff