Hi, I posted this on the Paratext site, but Steven White told me to post it here. Using exactly the same Paratext config Genesis and Exodus print out just fine. But Leviticus, Numbers, Deuteronomy and Matthew all print out with squares in the PDF output instead of nasalized vowels and the apostrophe which is used to represent the glottal? I have tried using both the Default config and my customized Genesis/Exodus config. But the results are the same? I would be very grateful if you can help me with this issue?
A guess: some of the characters have been entered in ‘decomposed’ form (separate vowel and nasalisation), others with ‘composed’ form. That might come about from different keyboard settings on different computers, or even the keyboard (or operating system) getting updated between you working on one book and the next.
You could prove that it’s not just a case of a different font by printing Gen and Lev in the same document, in which case one book should be with strange white rectangles (technically called tofu, apparently), the other with what you expect.

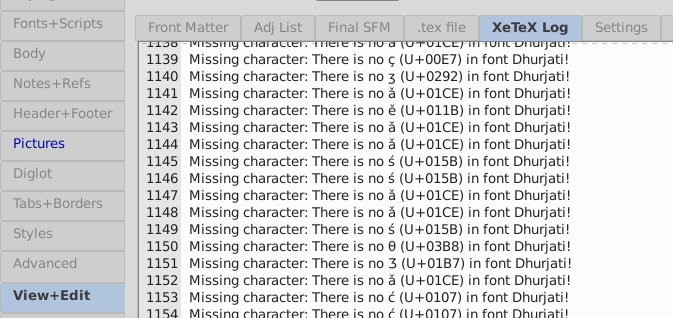
You can also get some precise information by looking at the log file (select full view, View+Edit tab, and then the XeTeX log sub-tab), where I expect you’ll see something like this towards the bottom of the log:
Search and replace is probably your friend at that point, but there are other solutions where the Paratext files remain unchanged and you just fix it for printing.
Hi David! Thank you for your reply! I found what you suspected, but I don’t know how to correct it? When you say search and replace I tried copying the char that is already working from Genesis and replacing the char that doesn’t work in Leviticus but the result was the same? Then, I looked at charmap and discovered that the chars in Paratext or PTXPrint are different from the chars in the font I use (MarkTNR Satere) even though this is the font I configured in both programs? I also tried replacing the chars in Leviticus copying the char from charmap but the result was still the same? In the following list you can see the unicode number for the missing chars and following the > the unicode number for the same char in the font I use. How do I correct this?
Missing character: There is no ꞌ (U+A78C) in font MarkTNR Satere! > ꞌ = U+0027
Missing character: There is no ỹ (U+1EF9) in font MarkTNR Satere! > ỹ = U+00FF
Missing character: There is no ẽ (U+1EBD) in font MarkTNR Satere! > ẽ = U+00E6
Missing character: There is no ĩ (U+0129) in font MarkTNR Satere! > ĩ = U+00F0
Very grateful for your help!
Hmm. I don’t think it’s recommended to require a specific font for a translation these days. It sounds like it might even be a pre-unicode or only semi-unicode font if it is using a code-point for dieresis (2 dots) and showing it as a tilde.
I would therefore encourage you to make the underlying text of the whole project into true unicode. Probably there are people here or on the Paratext site who can help you do that.
But, let us assume that for aesthetic reasons you need to use a specific font, which is using the wrong glyphs for certain letters.
Enabling full menus, you will see the advanced tab, you will see a checkbox you should set, ‘Apply changes.txt’:
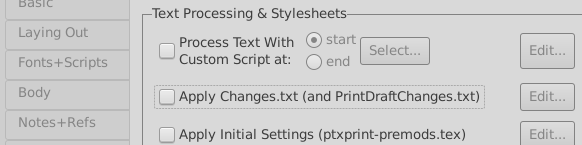
In that file (click on edit), you can apply regular changes, one per line, and also restrict the change to just a single verse.
The basic format is "old" > "new", you can specify unicode code-points by prefixing the number with \u For example:
"dh" > "ð"
"th" > "θ"
"\uA78C" > "\u0027"